AWK vs Big Data
There’s been a lot of talk about big data recently. Lots of people just shove data into
whatever software is currently all the rage (think Hadoop some time ago, Spark, etc) and
get excited with results that actually aren’t that amazing. You can get very decent results
by using the standard data processing toolset (awk/grep/sed/sort/xargs/find) paired with
understanding of what data you process and how the software works.
One of the best pieces of software I wrote was a data mining tool working on a dataset of approximately .5TB which is not that much. The trick was that it was completing queries on that dataset in subsecond timeframe. And I did spend quite a bit of time working on performance to achieve that result.
Thus being involved with this sort of tasks, I was amused to stumble upon this tweet:
Recently I got put in change of wrangling 25+ TB of raw genotyping data for my lab. When I started, using spark took 8 min & cost $20 to query a SNP. After using AWK + #rstats to process, it now takes less than a 10th of a second and costs $0.00001. My personal #BigData win. pic.twitter.com/ANOXVGrmkk
— Nick Strayer (@NicholasStrayer) May 30, 2019
The full story behind this tweet is a very nice reading of how the author was re-discovering plain-text tools with some fun and insightful quotes and other tweets like:
Me taking algorithms class in college: "Ugh, no one cares about computational complexity of all these sorting algorithms"
— Nick Strayer (@NicholasStrayer) March 11, 2019
Me trying to sort on a column in a 20TB #spark table: "Why is this taking so long?" #DataScience struggles.
and, a very true one:
gnu parallel is magic and everyone should use it.
Frankly, I think that quite a number of so-called Big Data applications can be re-done using
venerable text-processing tools and produce cheaper and faster results in the end. Which reminds
me another article where the author re-did a Hadoop task to process ~2Gb file with awk and ended up with 235x
speed increase:
I tried this out, and for the same amount of data I was able to use my laptop to get the results in about 12 seconds (processing speed of about 270MB/sec), while the Hadoop processing took about 26 minutes (processing speed of about 1.14MB/sec).
Review: Have you tried turning it off and on again?
Submitted by ipesin on November 7, 2017 - 11:38 am
When you attend a talk that starts with a Google engineer asking, “What would happen if all of the machines you are running on restarted right now?” you might get really worried. Think about the Google services we use on a daily basis and what would happen if they suddenly stopped working—Google Maps, for example. Hopefully, we’d be able to get home from the office, but if we were travelling or looking for a business location, that would become a disaster. What about Google Search? Would we be able to even do our job if it went down? I actually got scared for a moment, as thoughts like these raced through my mind. But then I realised that it is good that engineers at Google actually ask these same questions. This gives me hope.
Tanya Reilly’s talk on disaster recovery “Have You Tried Turning It Off and Turning It On Again?” was the best talk I attended at LISA17. It contained everything that makes a technical talk great: good natured humor, engaging speaking style, thoughtful analysis, shocking real-life examples, and nerdy stuff about handy tools. Even more: the talk was filled with phrases you just wanted to write down, so good they were. Jon Kuroda, who later delivered the closing plenary, couldn’t resist including one of them: “Because humans are terrible.”
People are extremely bad at dealing with complex systems, tedious and routine processes, repeatable processes; you name it, and we’re usually bad at it. Most of us know this, but do we do enough to mitigate this? For some years already there has been tribal knowledge that backups must be regularly tested to be sure you can recover from them. But how many organizations are actually doing it? And how many of those are doing it properly, i.e. not simply making sure you can read or extract backups, but actually starting all of their systems from the backup and then checking that everything works as it should? As Tanya said: “I’m not going to ask for show of hands, because it’s kind of embarrassing.”
The backup discussion is decades old, and it is still in quite bad shape. But the world is changing, and we are building more and more complex systems that consist of hundreds and thousands interdependent subsystems. These systems are also becoming increasingly reliable and failure resistant. The problem is that such systems are built gradually, and their complexity grows quite unnoticeably until no one really understands its interdependencies. At that point you realize that you can run the system, possibly even extend it, but if it really goes down, no one is sure how to bring it up again from the ground zero or how long it would take.
I had a similar experience about a decade ago, when the firm I worked for expanded from a dozen of servers to a hundred plus. Back then power outages were not uncommon where the firm’s office was located, and one day it took us more than four hours to bring the infrastructure back online because of dependencies, sometimes circular ones, that we hadn’t realized were there. After that event, we set up a task force to map all the dependencies we had, document them, make sure there were no circular dependencies, and create a recovery plan detailing in which order the infrastructure had to be powered back up. To steal another quote from the talk: “you don’t need a backup plan; you need a recovery plan.”
As you gather the dependencies, if there are more than a couple of dozens of them, you will find that it becomes difficult to process all of them and determine what shouldn’t be there (“because, you know, people are terrible”). As a nerdy diversion, Tanya spoke about and shared one of her favourite tools, which I happen to be fan of as well, graphviz. It’s so easy to visualize dependencies with it, you just put them one per line and surround with digraph { }:
$ cat sysexample.dot
digraph {
app1 -> db1
app1 -> cache1
app1 -> ldap
app1 -> dns
dns -> ldap
db1 -> ldap
db1 -> storage
ldap -> storage
storage -> dns
}
$ dot sysexample.dot -Tpng > sysex.png
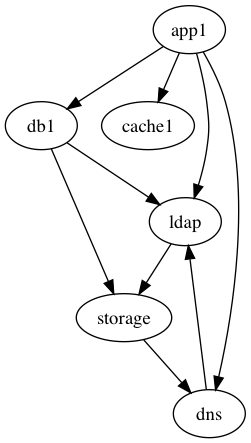
You get the visual representation which is easier to comprehend and notice a vicious cycle.
In my case, we really were looking for dependencies between the machines. These days, however, more and more functions are abstracted as microservices which run in containers, so dependencies are becoming more about services, and their interaction complexity continues to grow.
It is phenomenal how Tanya managed to make a talk on what I would call “the dark realms of the industry,” which are intrinsically sad and scary, fun and hope-inducing instead. It made me less scared and inspired to venture into and tackle these problems, which is essentially the point of the talk. Even better, start thinking about component dependencies before it becomes a problem, know them, include them into design phase, and constrain them.
Go and see the recording of this talk if you missed it. I am sure this is one of the talks which will have lasting effect and maybe at some point will help you in your career. The best way to listen to such talks is at the conference, certainly: you get the atmosphere, you get other people to talk to about it, and you have time to think about it while not being distracted by work. So if you missed the conference this year, come to the next LISA. Experiencing talks like this one first-hand makes you charged up with desire to fix things, address issues, and make the world a better place.
Review: Getting started with Docker and containers
Submitted by ipesin on November 1, 2017 - 3:38 pm
What makes a good conference so special? With vast amounts of information available virtually on any topic imaginable at a click’s distance, would it not be more efficient to spend time in comfortable home setting learning new technology?
Jérôme Petazzo’s “Getting Started with Docker and Containers” tutorial at LISA17 was a great example of the fact that despite all the online content and self-paced trainings, an outstanding lecturer can pass on a whole lot more information in limited amount of time than you could possibly hope to learn on your own. What is even more important, by listening to a person keen on the topic, you often pick up the same excitement yourself.
That was definitely the case with me. Containers are not a new concept under the sun: OpenVZ container technology is more than a decade old. In 2008, I led an effort at a firm where I worked back then to introduce containers for infrastructure services like LDAP, DNS, NTP, etc. A year ago, a project required simulation of thousands of Puppet nodes and to do so with reasonable resources, I opted for LXC/LXD containers with great success.
Being a long-time container user, however, Docker is something I was missing out on. For some odd reason, projects I have been working on lately do not leverage containers. I decided to catch up on it during LISA17. I did not anticipate how Jérôme’s training would affect me though.
To start, training was packed with outstanding educational approaches. Participants received access to personal cloud Cocker instances. This meant no one needed to litter their laptops with files and binaries, training time was not spent on resolving issues with tools not being correctly installed. There was no wifi collapse, because instances were provisioned ahead of time, and everyone was using low-bandwidth ssh access to work with them.
Next, Jérôme started to explain Docker capabilities and used fidget for that. This is a well known tool for generating nice renderings of text in ASCII art. I am using this tool to put hostnames or host functions in /etc/motd, so it is displayed when people log on to machines via ssh. The demo resonated with me so much, that an idea hatched in my mind how to improve the way I generate these titles for /etc/motd: a simple web application, that takes a font name and text as parameters and returns rendered ASCII caption. Then I could simply do a curl request during host provisioning or from Puppet and capture the output into /etc/motd file.
Finally, you hardly can get such a holistic end-to-end explanation and demonstration of container pipeline online – from coding on a developer’s workstation, through the build and test process, to the deployment in production.
My idea of a web app was so burning, that I simply went online during the first break and bought figlet.me domain, then wrote a simple web application in Go which takes parameters in URL and sends rendering back:
$ curl localhost:8080/?text=LISA17
# ### ##### # # #######
# # # # # # ## # #
# # # # # # # #
# # ##### # # # #
# # # ####### # #
# # # # # # # #
####### ### ##### # # ##### #
The only remaining thing was to put knowledge from the training to use and build a container with this application. In the evening I wrote a multistage Dockerfile, pushed it to Docker Hub, and then started it on a Docker host. Just 3 hours of training and not only I was able to set up the whole Docker development pipeline, I wanted to do it!
Now the web service is available for everyone to use (give it a try):
$ curl -d "font=slant" -d "text=USENIX LISA17 San Francisco" http://figlet.me/
__ _______ _______ _______ __ __ _________ ___ ________
/ / / / ___// ____/ | / / _/ |/ / / / / _/ ___// | < /__ /
/ / / /\__ \/ __/ / |/ // / | / / / / / \__ \/ /| | / / / /
/ /_/ /___/ / /___/ /| // / / | / /____/ / ___/ / ___ |/ / / /
\____//____/_____/_/ |_/___//_/|_| /_____/___//____/_/ |_/_/ /_/
_____ ______ _
/ ___/____ _____ / ____/________ _____ _____(_)_____________
\__ \/ __ `/ __ \ / /_ / ___/ __ `/ __ \/ ___/ / ___/ ___/ __ \
___/ / /_/ / / / / / __/ / / / /_/ / / / / /__/ (__ ) /__/ /_/ /
/____/\__,_/_/ /_/ /_/ /_/ \__,_/_/ /_/\___/_/____/\___/\____/
$ curl -d "font=straight" -d "text=USENIX LISA17 San Francisco" figlet.me
__ __ __ ___ __ __
/ \(_ |_ |\ ||\_/ | |(_ /\ /| / (_ _ _ |__ _ _ _. _ _ _
\__/__)|__| \||/ \ |__|__)/--\ | / __)(_|| ) || (_|| )(_|_)(_(_)
Would I do this if I watched YouTube video of a lecture sitting at home? Frankly, I doubt it. And this is why LISA is so special.
Conway's Life simulation in Go
Implemeting Conway’s life is one of the first things I do when exploring a new programming language.
Conway’s Game of Life, also known as the Game of Life or simply Life, is a cellular automaton devised by the British mathematician John Horton Conway in 1970. It is the best-known example of a cellular automaton. Ever since its publication, Conway’s Game of Life has attracted much interest because of the surprising ways in which the patterns can evolve.
This time I wrote a version that can generate text-mode and animated GIF representations and load predefined starting configuration from LIF files:

Pi-heptomino is a common heptomino that stabilizes at generation 173, leaving behind six blocks, five blinkers and two ponds.

Thunderbird is a methuselah that stabilizes after 243 generations. Its stable pattern has 46 cells and consists of four blinkers, four beehives and two boats.
The Schelling Model of Ethnic Residential Dynamics
In 1971, the American economist Thomas Schelling created an agent-based model that might help explain why segregation is so difficult to combat. His model of segregation showed that even when individuals (or “agents”) didn’t mind being surrounded or living by agents of a different race, they would still choose to segregate themselves from other agents over time! Although the model is quite simple, it gives a fascinating look at how individuals might self-segregate, even when they have no explicit desire to do so.
Models are my favourite coding excercises. Often not too difficult to implement, but almost always very captivating. This time it’s the segregation model in two alogrithm variations:
- when the agent becomes dissatisfied, it moves to a vacant spot where it will be satisfied
- when the agent becomes dissatisfied, it moves to a random vacant spot

Dissatisfied agent moves to a vacant spot where it will be satisfied

Dissatisfied agent moves to a random vacant spot
I find it fascinating to observe how these clusters are formed even without a clear agent preference for uniformity!