Review: Have you tried turning it off and on again?
Submitted by ipesin on November 7, 2017 - 11:38 am
When you attend a talk that starts with a Google engineer asking, “What would happen if all of the machines you are running on restarted right now?” you might get really worried. Think about the Google services we use on a daily basis and what would happen if they suddenly stopped working—Google Maps, for example. Hopefully, we’d be able to get home from the office, but if we were travelling or looking for a business location, that would become a disaster. What about Google Search? Would we be able to even do our job if it went down? I actually got scared for a moment, as thoughts like these raced through my mind. But then I realised that it is good that engineers at Google actually ask these same questions. This gives me hope.
Tanya Reilly’s talk on disaster recovery “Have You Tried Turning It Off and Turning It On Again?” was the best talk I attended at LISA17. It contained everything that makes a technical talk great: good natured humor, engaging speaking style, thoughtful analysis, shocking real-life examples, and nerdy stuff about handy tools. Even more: the talk was filled with phrases you just wanted to write down, so good they were. Jon Kuroda, who later delivered the closing plenary, couldn’t resist including one of them: “Because humans are terrible.”
People are extremely bad at dealing with complex systems, tedious and routine processes, repeatable processes; you name it, and we’re usually bad at it. Most of us know this, but do we do enough to mitigate this? For some years already there has been tribal knowledge that backups must be regularly tested to be sure you can recover from them. But how many organizations are actually doing it? And how many of those are doing it properly, i.e. not simply making sure you can read or extract backups, but actually starting all of their systems from the backup and then checking that everything works as it should? As Tanya said: “I’m not going to ask for show of hands, because it’s kind of embarrassing.”
The backup discussion is decades old, and it is still in quite bad shape. But the world is changing, and we are building more and more complex systems that consist of hundreds and thousands interdependent subsystems. These systems are also becoming increasingly reliable and failure resistant. The problem is that such systems are built gradually, and their complexity grows quite unnoticeably until no one really understands its interdependencies. At that point you realize that you can run the system, possibly even extend it, but if it really goes down, no one is sure how to bring it up again from the ground zero or how long it would take.
I had a similar experience about a decade ago, when the firm I worked for expanded from a dozen of servers to a hundred plus. Back then power outages were not uncommon where the firm’s office was located, and one day it took us more than four hours to bring the infrastructure back online because of dependencies, sometimes circular ones, that we hadn’t realized were there. After that event, we set up a task force to map all the dependencies we had, document them, make sure there were no circular dependencies, and create a recovery plan detailing in which order the infrastructure had to be powered back up. To steal another quote from the talk: “you don’t need a backup plan; you need a recovery plan.”
As you gather the dependencies, if there are more than a couple of dozens of them, you will find that it becomes difficult to process all of them and determine what shouldn’t be there (“because, you know, people are terrible”). As a nerdy diversion, Tanya spoke about and shared one of her favourite tools, which I happen to be fan of as well, graphviz. It’s so easy to visualize dependencies with it, you just put them one per line and surround with digraph { }:
$ cat sysexample.dot
digraph {
app1 -> db1
app1 -> cache1
app1 -> ldap
app1 -> dns
dns -> ldap
db1 -> ldap
db1 -> storage
ldap -> storage
storage -> dns
}
$ dot sysexample.dot -Tpng > sysex.png
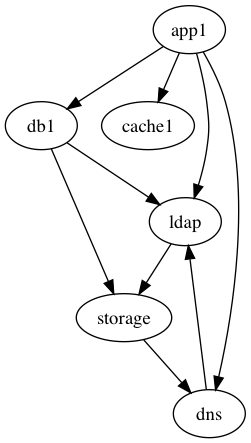
You get the visual representation which is easier to comprehend and notice a vicious cycle.
In my case, we really were looking for dependencies between the machines. These days, however, more and more functions are abstracted as microservices which run in containers, so dependencies are becoming more about services, and their interaction complexity continues to grow.
It is phenomenal how Tanya managed to make a talk on what I would call “the dark realms of the industry,” which are intrinsically sad and scary, fun and hope-inducing instead. It made me less scared and inspired to venture into and tackle these problems, which is essentially the point of the talk. Even better, start thinking about component dependencies before it becomes a problem, know them, include them into design phase, and constrain them.
Go and see the recording of this talk if you missed it. I am sure this is one of the talks which will have lasting effect and maybe at some point will help you in your career. The best way to listen to such talks is at the conference, certainly: you get the atmosphere, you get other people to talk to about it, and you have time to think about it while not being distracted by work. So if you missed the conference this year, come to the next LISA. Experiencing talks like this one first-hand makes you charged up with desire to fix things, address issues, and make the world a better place.